Обзор последних версий программ машинного перевода смотрите здесь!
Переведутся ли переводчики?
Впервые опубликовано в уже несуществующем журнале Мир Internet, #8 за 2002 год.
- Введение
- Немного истории
- "О сбыче мечт", или "А в чем, собственно, проблема?"
- Туда-сюда-обратно…
- Что делать?
Введение
За окном шел снег и рота красноармейцев. The snow and company красноармейцев went for window. Павел Асе & Нестор Бегемотов, 1987. СОКРАТ IT, перевод, 2002 Однажды для прямого перевода была выбрана фраза: "Дух силен, а плоть слаба". Вторая машина неверно "поняла" английское слово spirit, в результате обратный перевод гласил: "Спирт крепок, а мясо протухло". Р. Смоллион "Как же называется эта книга?", 1979.Оригинал: "Дух силен, а плоть слаба". Перевод: "The Spirit is strong, and the flesh is weak". Обратный перевод: "Дух силен, и плоть слаба". PROMT, 2002.
Машинному переводу (Machine Translation, MT) u его "младшему брату" автоматизированному онлайновому переводу текстов и веб-страниц посвящена уже не одна сотня статей. Интересно, что отношение пользователей к программам-переводчикам редко бывает нейтральным: люди склонны либо не замечать их недостатков, либо, наоборот, игнорировать их достоинства. Обе этих крайних оценки, однако, достаточно далеки от реальности ("истина где-то рядом", как любит повторять агент Малдер из Секретных материалов). Именно об этом - на примере переводов с английского на русский и обратно мы и говорим в статье.
Немного истории
Автоматический ("машинный") перевод текстов исторически был одной из первых задач, решение которых люди попытались переложить на вычислительные устройства. По-видимому, первым, кто попытался получить правительственные субсидии на развитие вычислительной техники, был выдающийся математик XIX века Чарльз Бэббидж. В числе благ, которые он сулил британскому правительству в случае поддержки его проекта вычислительной машины, было обещание, что когда-нибудь эта машина сможет автоматически переводить разговорную речь.
Другие изобретатели тоже пытались создать механические переводящие устройства еще до наступления компьютерной эры. Например, Петр Троянский в середине 1930-х годов получил в СССР патент, предложив не только автоматический двуязычный словарь, но и схему кодирования межъязыковых грамматических ролей, основанную на языке эсперанто. Тем не менее, сейчас принято считать, что основные принципы современного машинного перевода были изложены только в 1947 году в письме директора естественнонаучного отделения Рокфеллеровского фонда Уоррена Уивера к Норберту Винеру.
За этим письмом последовала активная дискуссия среди специалистов, а уже через пять лет был переведен знаменитый Джорджтаунский эксперимент, имевший грандиозный успех. В ходе него был продемонстрирован электронный словарь, содержавший всего 250 слов и шесть грамматических правил. Это обеспечивало перевод полусотни заранее отобранных предложений.
После этого эксперимента возможности компьютерного перевода рассматривались в самом радужном свете, а будущее переводчиков-профессионалов, наоборот, представлялось очень и очень проблематичным. Однако уже в 1966 году консультативный комитет по автоматической обработке языка при Национальной академии наук США (ALPAC) представил крайне пессимистический отчет о перспективах машинного перевода, после чего почти все работы в этой области были свернуты и практически заморожены до самого конца 1970-х годов (причем не только в США, но и в СССР, и в большинстве стран Европы). Только падение "железного занавеса", развитие международной коммерции и Интернета дали новый мощный толчок (подкрепленный финансовыми вливаниями) для исследований в этой сфере.
С середины 90-х годов перевод веб-страниц "на лету" постепенно становится одной из приоритетных задач всех систем машинного перевода. При этом, конечно, никто всерьез не рассматривает "чисто машинный перевод" как окончательный. Основные работы сейчас ведутся в сферах, которые принято обозначать аббревиатурами MAHT (Machine-Aided Human Translation, человеческий перевод с привлечением машин) и HAMT (Human-Aided Machine Translation, машинный перевод с участием человека).
"О сбыче мечт", или "А в чём, собственно, проблема?"
Первый источник проблем машинного перевода - это многозначность слов в любом естественном языке (профессиональные лингвисты стараются различать полисемию и омонимию, но, с точки зрения переводчиков, и то, и другое приводит к одинаковым трудностям), а также существование устойчивых словосочетаний и фразеологических оборотов. Причем, эти явления существуют как в языке, с которого делается перевод, так и в том языке, на который переводится. Вот один из примеров, увиденный автором буквально на днях. Слоган фирмы Western Union - "The fastest way to transfer money world wide" переведён на русский язык так: "Western Union - самый быстрый способ перевести деньги по всему миру". Что называется, "попали"… Во-первых, оборот "перевести деньги" имеет ещё и значение "протратиться" (сравните: "деньги у него совсем перевелись"), а во-вторых, очень давит схожесть конструкции "перевести деньги по миру" с русской идиомой "пустить по миру". Более явную антирекламу придумать очень сложно… (Зато запоминается. Может быть, в этом и состояла задумка переводчика?!)
Второй источник погрешностей при переводе - требования языка к соблюдению определенного порядка слов в предложениях, то есть к способу объединения отдельных слов в связный текст.
Принято считать, что в русском языке порядок слов свободный: вы можете как угодно переставить слова в фразе "я выпил молоко" - и собеседник вас поймет однозначно. Исключения бывают, но сравнительно нечасто ("мать любит дочь" не то же самое, что "дочь любит мать"). В то же время, в английском, да и в большинстве европейских (германских и романских) языков, соблюдение вами правильного порядка слов жизненно необходимо для того, чтобы ваш собеседник смог понять, что же вы ему пытались сообщить.
И, наконец, третий источник лингвистических затруднений - невозможность формально описать лингвистические закономерности. Например, школярские представления о том, что в русском языке существует всего 36 категорий имени существительного (три рода, три склонения, две категории одушевленности, имена собственные/нарицательные), увы, совершенно не подтверждаются живым языком. Слова "глаз", "луч", "матрац", "стул" и "стол" любой школьник отнесет к нарицательным существительным мужского рода, второго склонения, неодушевленным. Однако в именительном падеже множественного числа будут "глазА", "лучИ", "матрацЫ", "стулЬЯ", а в родительном падеже множественного числа разнообразие вариантов еще больше: "глаз", "лучЕЙ", "матрацЕВ", "стулЬЕВ", "столОВ".
Может показаться, что переводить текст с английского языка (с "жестким" порядком слов) на русский (со свободным порядком) проще, чем наоборот. Так ли это? К сожалению, нет.
Туда-сюда-обратно…
Сразу хочу отметить, что я не занимался полноценным тестированием различных систем машинного перевода. За рамками этой статьи остались такие важные (для пользователей) параметры, как скорость перевода, "продвинутость" интерфейсов, поддержка других языков и направлений перевода (я ограничил себя и читателей только рамками русско-английского и англо-русского переводов).
В качестве "подопытного кролика" я взял одну логическую задачку:
"You are given 12 identical-looking coins, one of which is counterfeit and weighs slightly more or less (you don't know which) than the others. You are given a beam balance which lets you put the same number of coins on each side and observe which side (if either) is heavier. How can you identify the counterfeit and tell whether it is heavy or light, in 3 weighings?"
Вот ее "человеческий" (вольный) перевод на русский: "У вас есть 12 одинаковых по виду монет, одна из которых - фальшивая и весит немного больше или меньше, чем остальные (вы не знаете, какая именно.) Имеются двухчашечные весы, на чаши которых вы можете класть равное число монет и смотреть, какая из чаш перевесила (или весы остались в равновесии). Как за 3 взвешивания определить фальшивую монету и узнать, легче она или тяжелее остальных?"
Замечу, что при переводе мне пришлось поменять порядок слов в нескольких предложениях. (Тем самым миф о свободном порядке слов в русском языке уже развенчан). А вот как переводит этот текст система автоматического перевода семейства PROMT (использовалась PROMT Internet XV Premium, 2002 г.):
"Вам дают 12 идентично-выглядящих монет, одна из которых - подделка и весит слегка более или менее (Вы не знаете который) чем другие. Вам дают баланс луча, который позволяет Вам помещать тот же самый номер (число) монет на каждой стороне и наблюдать (соблюдать), которая сторона (если любой) является более тяжелым. Как Вы можете идентифицировать подделку и сообщать, является ли это тяжелым или легким в 3 взвешиваниях?"
Обратите внимание на "баланс луча". Эта ошибка вызвана, как легко понять, отсутствием в словаре словосочетания "beam balance", означающего рычажные весы. Я не поленился и проверил перевод того же текста на одной из предыдущих версий PROMT'a, к которой были докуплены и подключены специализированные словари, в том числе физический и математический. Рычажные весы" в переводе появились, но зато в конце текст стал хуже: слово light ("легкий") оказалось переведенным как "свет"…
Ладно, не беда. Попробуем исправить это - благо, локальная версия PROMT'a позволяет создавать и редактировать собственные пользовательские словари. После десятиминутной работы со словарными статьями перевод приобретает следующий вид:
"Вам дают 12 идентично-выглядящих монет, одна из которых - подделка и весит слегка более или менее (Вы не знаете который) чем другие. Вам дают рычажные весы, который позволяет Вам помещать тот же самый номер (число, количество) монет на каждой стороне и наблюдать (соблюдать), которая сторона (если любой) является более тяжелым. Как Вы можете идентифицировать (определить) подделку и сообщать, является ли это тяжелым или легким, в 3 взвешиваниях?"
Давайте теперь немного "причешем" этот текст: не меняя порядка слов и самих слов, уберем все дублирующие варианты и чуть-чуть подправим падежи:
"Вам дают 12 идентично-выглядящих монет, одна из которых - подделка и весит слегка больше или меньше (Вы не знаете который) других. Вам дают рычажные весы, которые позволяют Вам помещать то же самое количество монет на каждой стороне и наблюдать, какая сторона (если любой) является более тяжелой. Как Вы можете идентифицировать (определить) подделку и сообщить, является ли она тяжелой или легкой, в 3 взвешиваниях?"
Пропустим через PROMT этот текст в обратном направлении и сравним его с оригиналом:
"То you give 12 identically-appeared coins, one of which - a fake and weighs slightly more or less (you do not know which) others. To you give lever balance which allow you to place the same quantity (amount) of coins on each party (side) and to observe, what party (side) (if anyone) is heavier. How you can define (determine) a fake and inform, whether she (it) is heavy or easy, in 3 weighings?"
Что мы видим? Если отвлечься от ошибочно переведенных связок местоимение - глагол ("to you give" вместо "you are given"), останется следующее: "counterfeit", вначале переведенная как "подделка", после обратного перевода стала "фальшивкой" ("fake"). Рычажные весы стали "lever balance" вместо "beam balance" (и неудивительно, ведь мы добавили соответствующий перевод только с английского на русский, но не наоборот). Аналогичная метаморфоза (и по той же причине) произошла с "количеством", превращенным в "quantity" вместо исходного "number". Однако слово "light", поначалу правильно переведенное системой как "легче", превратилось в "easy" (то есть в "проще").
Кажется, на этом примере ясно видны все основные трудности, возникающие при автоматизировании перевода.
Для полноты картины приведу результаты работы других систем перевода на той же логической задачке:
Переводчик "Сократ" (СОКРАТ Интернет 3.0 базовый), англо-русский перевод:
"Вы даны 12 идентичных смотреть монет, одно из которого - подделка и взвешивает чуть более или менее (Вы не знаете какое) чем другие. Вы даны лучевой баланс, который позволяет, чтобы Вы поместили то же количество монет на каждую сторону и наблюдали какую сторону (если также), тяжелое. Как можете ли Вы идентифицировать подделку и сообщать независимо это - тяжелый или свет, в 3 взвешивании?"
Обратный перевод того же "Сократа" (без всякой предварительной коррекции русского текста):
"You are given 12 identical to look the coins, one of which - a forgery and weights slightly more or less (You do not know what) than others. You are given beam balance, which allows that You have placed ditto amount of the coins on each side and observed what side (if also), heavy. As can You identify the forgery and report independently this - heavy or light, in 3 взвешивании?"
Сравните этот вариант с первоначальным. Полного совпадения, кстати, быть и не должно, но то, что слово "взвешивании" осталось непереведенным, огорчает.
Следующий "кандидат в переводчики" - BabelFish. Он умеет переводить только с русского на английский, поэтому мне пришлось подсунуть ему "человеческий" русский перевод задачки.
В результате получилось вот что:
You have 12 identical with respect to form coins, one of which false and weighs somewhat more or less than the rest (you do not know, what precisely). There are two-cup weights, at cups of which you can place the equal number of coins and look, which of the cups hung somewhere else (or weights they remained in the equilibrium). As for 3 weighing to determine false coin and to learn, more easily it or is heavier than rest?
Очень сложно объяснить в двух словах, что здесь неправильно. Грубо говоря - почти все: по-английски так не говорят.
И еще один подобный русско-английский эксперимент - работал онлайновый переводчик Dialing, о котором его создатели честно сообщают, что он сделан наполовину. Результат:
You have 12 identical on form coins, one which false weighs somewhat bigger or less, you do not ostal'noy know, what именно. 2-chashechnyy weights on which caps you can lay the equal number of coins and look which of the caps outweighed (, or the weights remained in balance) are had. How, to determine for the 3 calculations and to learn the counterfeit coin it is lighter or more difficult than ostal'noy?
Конечно, записанные латиницей "2-chashechnyy" и "ostal'noy" умиляют, но… Снова видим непереведенное слово "именно" и несколько грубых ошибок. Однако хочу обратить внимание читателей на одну особенность этого перевода: в нем (и только в нем) из первого предложения исчезли скобки. Это связано с тем, как в Dialing реализована функция перевода: он сначала производит морфологический и синтаксический разбор текста, потом "переводит" структуру фраз и порядок слов в них так, как это принято делать в английском языке, и только потом начинает переводить отдельные слова. То есть в перспективе (когда работа над этим переводчиком будет закончена) у него есть все шансы превзойти конкурентов по качеству перевода.
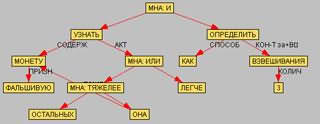
Рис.1 комментирует сказанное: на нем изображен синтаксический разбор Dialing'ом вопросительной фразы "Как за 3 взвешивания определить фальшивую монету и узнать, легче она или тяжелее остальных?" Вы можете сами поэкспериментировать с другими фразами. А на рис.2 для разбора той же фразы построен граф - схема, демонстрирующая связи и отношения между словами (например, система распознала, что слово "фальшивую" является признаком слова "монету").
Что делать?
Позвольте сформулировать несколько выводов (может быть, весьма спорных, но…).
Первое. Не стоит ожидать от машинного перевода больше, чем он в принципе может дать. Сказочки типа "моя дочь, совершенно не зная французского языка ![]() , использовала программу X и в течение года переписывалась с французом, а он ничего не заподозрил" оставим для рекламных агентов. Скорее всего, француз как истинный кавалер проявил галантность и не стал колоть глаза своей русской подруге ее безграмотностью.
, использовала программу X и в течение года переписывалась с французом, а он ничего не заподозрил" оставим для рекламных агентов. Скорее всего, француз как истинный кавалер проявил галантность и не стал колоть глаза своей русской подруге ее безграмотностью.
Второе. Конечно, рано или поздно машинные переводчики достигнут того уровня, когда улучшить и поправить их перевод сможет только настоящий профессионал. Но сейчас говорить об этом все еще преждевременно: грубые ошибки видны невооруженным глазом.
Третье. Если вы действительно не знаете иностранного языка, но хотите, чтобы собеседники вас понимали, будьте проще! Стройте фразы так, чтобы они не допускали двоякого толкования. Используйте короткие (и простые по структуре) предложения. Откажитесь от причастных и деепричастных оборотов. Исключите из употребления любую идиоматику и игру слов. Наконец, постоянно держите в уме, что вы объясняете первокласснику принцип работы синхрофазотрона…
И последнее. Если вы знаете иностранный язык, не пытайтесь сначала написать свой текст по-русски, потом перевести его с помощью компьютера и вручную исправлять ошибки. Лучше делайте наоборот: сразу пишите текст на иностранном языке, а потом пропускайте его через "иностранно-русский" переводчик. Если результат машинного перевода будет более или менее понятным, значит, все в порядке. Если нет - правьте оригинал до тех пор, пока вас не устроит качество русского перевода.
© Константин Кноп
Впервые опубликовано в уже несуществующем журнале Мир Internet, #8 за 2002 год.
хостинг для сайтов © Langust Agency 1999-2024, ссылка на сайт обязательна
