28/12/2016 Переведётся всё
Впервые опубликовано на сайте издания N+1
На сайте издания N+1 была опубликована авторская статья о программах-переводчиках ![]() .
.
Ниже материалы статьи приведены полностью.
Программы-переводчики давно доказали свою полезность, но много ли языков входит в стандартный набор любого крупного онлайн-переводчика?
Программисты из «Яндекса» задумались над этой проблемой: ведь только в России существует около двухсот так называемых «малых» языков, на которых люди говорят и пишут тексты - и почему не дать им возможность переводить их на другие, как «большие», так и «малые» языки? По просьбе N + 1 разработчик группы машинного перевода «Яндекса» Антон Дворкович рассказал, как можно научить машину переводить с горномарийского на идиш и обратно ![]() .
.
Языки «большие» и «малые»
В мире существует великое множество языков. На многих из них написано достаточно книг и других документов, которые со временем были оцифрованы и в итоге попали в крупные поисковики, такие как «Яндекс». Однако существует категория так называемых малых языков, на которых говорит не так много людей и которые оставили после себя совсем мало печатных или письменных документов. Оцифровано же их ещё меньше.
Если зайти в любой популярный онлайн-переводчик, мы увидим там, в основном, знакомые каждому языки - почти никакой экзотики. И это неспроста: машинный перевод, который используют онлайн-переводчики, работает благодаря анализу и сопоставлению больших массивов данных. Но как перевести с языков, на которых совсем мало информации? Ведь мы не можем взять знания какого-нибудь профессионального переводчика и загнать их в программу, мы должны научить её переводить такие тексты автоматически на основе обработанных данных.
У нас в «Яндексе» было несколько разрозненных исследований на эту тему, но до недавнего времени не получалось объединить это в рамках одной технологии. Всё изменилось, когда к нам обратился коллега из офиса «Яндекса» в Голландии. Выяснилось, что он является носителем редкого языка папьяменто, на котором говорит несколько сотен тысяч человек на Карибских островах. Его просьба добавить этот язык в «Яндекс.Переводчик» послужила толчком к тому, чтобы наконец систематизировать имеющиеся знания. Мы начали работать.
Язык как совокупность моделей
В основе статистического машинного перевода, на который опирается «Яндекс.Переводчик», долгое время лежали исключительно лексические модели, т.е. такие модели, которые не учитывают родственные связи между различными словами и другие лингвистические характеристики. Проще говоря, слова «мама» и «маме» - это два совершенно разных слова с их точки зрения; такие же разные, как слова «мама» и «бегать», например.
Около 15 лет назад в индустрии появилось понимание, что качество статистического машинного перевода можно улучшить, если дополнить сугубо лексическую модель ещё и моделями морфологии (словоизменения и словообразования) и синтаксиса (построения предложений). В отличие от систем, основанных на ручных правилах, модели морфологии и синтаксиса можно формировать автоматически на основе статистики. Вот простой пример с тем же словом «мама»: если «скормить» нейронной сети тысячи текстов, содержащих это слово в различных формах, то сеть «поймёт» принципы словообразования и научится предсказывать правильную форму в зависимости от контекста.
Переход от простой модели к комплексной хорошо отразился на общем качестве, но для её работы по-прежнему нужны сотни тысяч примеров, которые трудно найти для небольших языков. В итоге построить эффективный перевод «малых» языков нам помог тот факт, что многие языки связаны между собой.
Родственные связи
Мы отошли от традиционного восприятия каждого языка как независимой системы, и стали учитывать родственные связи между ними. На практике это означает, что если у нас есть язык, для которого нужно построить перевод, но данных для этого недостаточно, то можно взять другие, более «крупные» и родственные языки. Их отдельные модели (морфология, синтаксис, лексика) можно использовать для заполнения пустот в моделях «малого» языка. Может показаться, что речь идёт о слепом копировании слов и правил между языками, но технология работает несколько умнее.
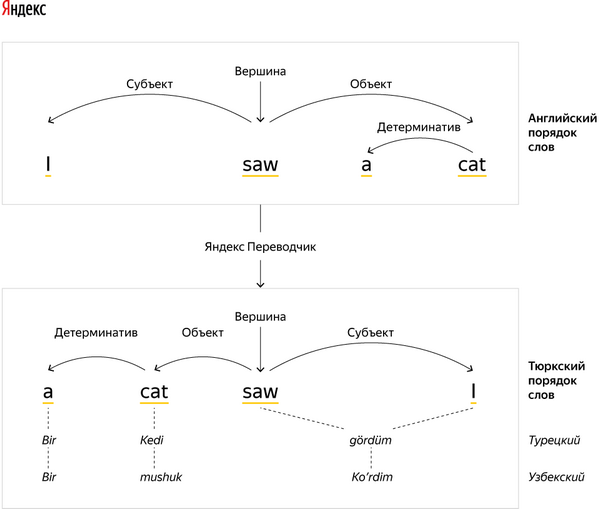
Начальный этап работы над любым «малым» языком ничем не отличается от создания переводчика для «большого» языка. Мы загружаем в машину все доступные нам материалы и запускаем процесс. Она проходит по параллельным текстам, написанным на разных языках, и строит распределение вероятностей перевода для каждого найденного слова. Для этого можно, но не обязательно, применять нейронные сети - зачастую более простых инструментов вполне хватает. Система, глядя на параллельные тексты, пополняет свой словарный запас и запоминает переводы. Для больших языков, где примеров миллионы, больше ничего делать не надо - система найдёт не только все возможные слова, их формы и запомнит их переводы, но и учтёт разные случаи их применения в зависимости от контекста. С небольшим языком мы можем смоделировать ядро (самые частотные слова и конструкции в языке), но примеров применения окажется недостаточно для учёта словообразования и полного покрытия всех слов. Технология, которая лежит в основе нашего подхода, работает несколько глубже с уже имеющимися примерами и использует знания о других языках.
Возьмём для примера татарский и башкирский языки - два очень близких тюркских языка. Они различаются некоторыми звуками: например, «девушка» будет по-татарски «кыз», а по-башкирски «ҡыҙ», лестница по-татарски «баскыч», а по-башкирски «баҫҡыс». Но их лингвистические характеристики - и морфология, и синтаксис - практически одинаковы. Наша технология умеет понимать это различие звуков и заимствовать какие-то слова при переводе с обоих языков, если на каком-то из них окажется недостаточно информации.
Или взять идиш, который возник в X-XIV веках на основе верхненемецких диалектов - тех же, которые легли в основу современного немецкого языка. Поэтому очень многие слова в идише и немецком одинаковы или очень похожи. Идиш использует еврейский алфавит, но, в отличие от иврита, обозначает на письме все гласные - кроме слов древнееврейского происхождения, которые сейчас принято писать так же, как в иврите. В остальном в идише фонетический принцип письма, и это даёт возможность, если немецкое слово и слово на идише совпадают, автоматически транслитерировать их. Можно посмотреть на марийский язык: в нём с самого появления письменности (в XIX веке) различались два литературных варианта - луговой (восточный) и горный (западный). Они отличаются фонетически и в некоторой степени лексически; кроме того, в горном марийском языке есть гармония гласных, отсутствующая в луговом. В целом языки очень похожи и более-менее взаимопонимаемы, но из-за того, что луговых марийцев намного больше, марийским языком «по умолчанию» обычно считается луговой. По этой же причине текстов на луговом марийском гораздо больше, и за основу перевода мы берём их.
В случае если машине не известна даже начальная форма слова, но понятна история происхождения языка, машина может на основе всей доступной ей информации из корпуса всех языков понять, какое слово ближе всего к неизвестному - получается, что таким образом она понимает не только словарное значение, но и контекстное. Вернёмся к примерам на идише: в этом языке есть слово ןרעטש (штерн), которое означает «звезда» (немецкое Stern) и «лоб» (нем. Stirn). Во фразе «на небе много звёзд», очевидно, имеется в виду первое значение, а во фразе «ударил его по лбу» - второе. Ещё есть слово קנאב (банк), которое значит «банк» или «скамья», которые по-немецки тоже одинаковы (Bank), но различаются во множественном числе («скамьи» будет Bänke, а «банки» - Banken), а на идише всегда одинаковы (קנעב - бэнк). Наша технология умеет автоматически выучивать эти слова без готовых примеров и ручного вмешательства.
Практическая и социальная польза
Конечно, перевод с малых языков не может обойтись без своего рода «асессора» - человека, который знает этот язык и может по особым методикам определить, насколько точным оказался перевод. В нашем случае пригодилась помощь многочисленных региональных организаций, которые в России занимаются исследованием и сохранением малых языков. Например, в создании марийско-русского перевода нам очень помогли сразу несколько организаций, и мы вели работу с Марийским научно-исследовательским институтом языка, литературы и истории им. В.М. Васильева (МарНИИЯЛИ) и Республиканским центром марийской культуры (РЦМК), обеспечившими лингвистическую поддержку и подготовку эталонных марийско-русских переводов для оценки качества перевода. А при создании переводчика с удмуртского языка мы познакомились с группой энтузиастов, которые занимаются составлением его корпуса. В регионах вообще достаточно неравнодушных к судьбе своих языков людей, которые готовы помочь в создании корректного переводчика. Учитывая размеры нашей страны и количество разных народностей, которые в ней живут, работы по машинному переводу с других языков ещё очень много.
Любые дополнительные данные при должном использовании позволяют улучшить качество перевода - мы рассчитываем, что разработанная нами технология использования данных на родственных языках в перспективе будет внедрена и для «больших» направлений и поможет в целом лучше понимать связи между языками, а, следовательно - точнее переводить тексты. Поэтому можно сказать, что эта технология - не столько про «малые» языки, сколько про установление связей между разными языками мира. В этом смысле она прекрасно ложится в знаменитую модель noisy channel, по которой выходит, что в концепции машинного перевода мы все говорим на одном языке, но интерпретация доходит до нас с ошибками, и задача машины - эти ошибки исправить. Но это уже другая, большая и интересная история.
© Антон Дворкович, разработчик группы машинного перевода «Яндекса»
Впервые опубликовано на сайте издания N+1
хостинг для сайтов © Langust Agency 1999-2024, ссылка на сайт обязательна
