28/02/2018 Как работает нейросеть Google Translate
Впервые опубликовано на сайте Cossa.ru
На сайте Cossa.ru была опубликована заметка о Google Translate.
Ниже материалы заметки приведены полностью.
Рассказывают представители онлайн-школы EnglishDom  .
.
Google Translate по праву считается машинным переводчиком № 1 в мире. Сервис поддерживает работу со 103 языками и каждый день обрабатывает около 500 миллионов запросов.
В 2016 году Google представила систему нейронного машинного перевода (GNMT), которая использует искусственную нейронную сеть для улучшения качества перевода.
Действительно ли перевод стал лучше с её помощью? Давайте узнаем!
Тонкости нейронного перевода: как это работает
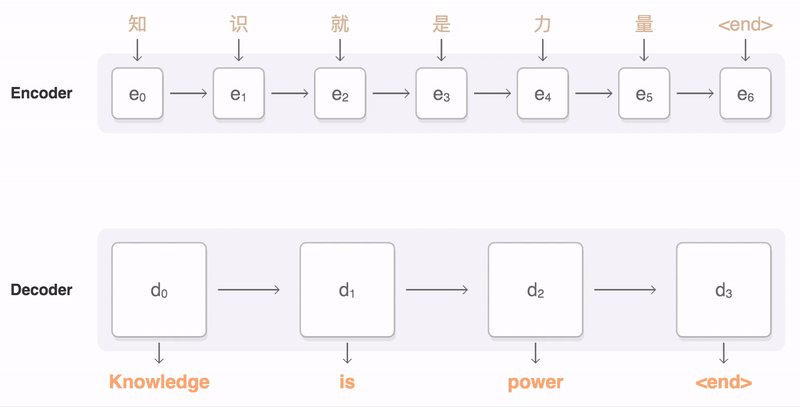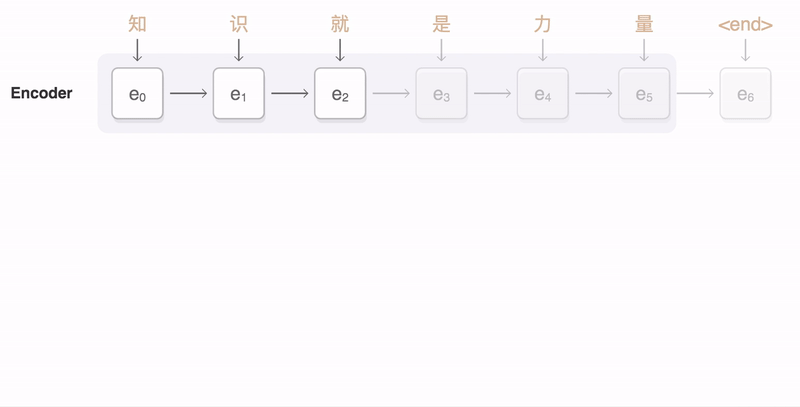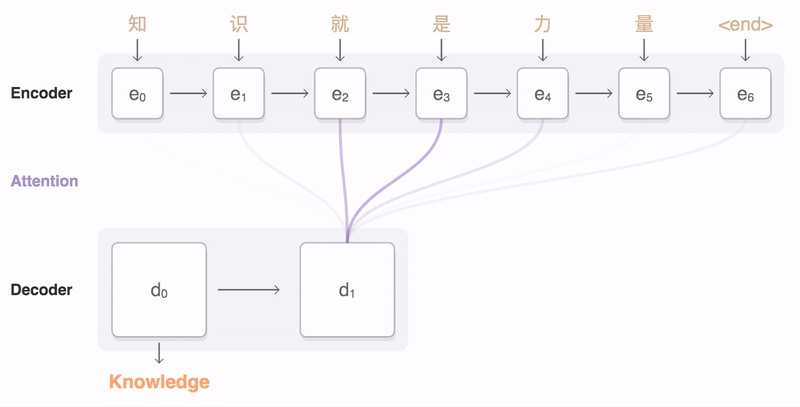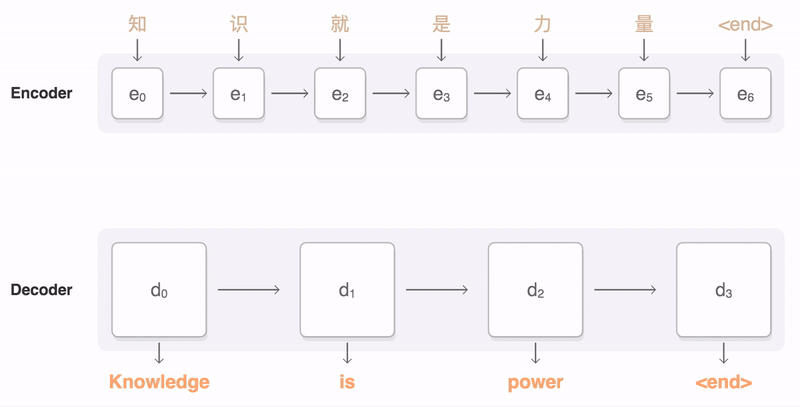
Нейронная модель машинного перевода использует иные принципы работы с текстом, чем стандартный статистический метод перевода.
До появления нейронных сетей перевод проводился пословно - система переводила отдельные слова и фразы с учётом грамматики. Поэтому при сложных оборотах или длинных предложениях качество перевода оставляло желать лучшего.
GNMT же переводит предложение целиком, учитывая контекст. Система не запоминает сотни вариантов перевода фраз - она оперирует семантикой текста.
При переводе предложение разбивается на словарные сегменты. Затем с помощью специальных декодеров система определяет «вес» каждого сегмента в тексте. Далее вычисляется максимально вероятные значения и перевод сегментов. Последний этап - соединить переведённые сегменты с учётом грамматики.
Как действует алгоритм переводчика
Чтобы понять принципы работы нейронного перевода от Google, давайте немного углубимся в технические детали.
В основе Google Neural Machine Translation лежит принцип работы рекуррентных двунаправленных нейронных сетей (Bidirectional Recurrent Neural Networks), работающих с матричными вычислениями вероятности.
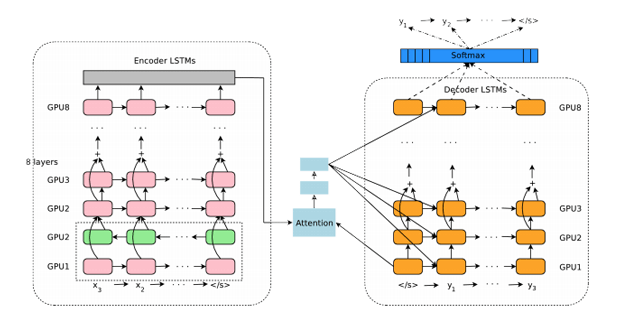
Разберём подробнее, что всё это значит.
«Рекуррентный» говорит, что система вычисляет значение слова или фразы на основе предыдущих значений в последовательности. Именно это позволяет системе учитывать контекст и правильно выбирать среди разных вариантов перевода.
К примеру, в словосочетании «лук из красного дерева» слово «лук» система переведёт как «bow», а не «onion».
Двунаправленность означает, что нейросеть разделена на два потока - анализирующий и синтезирующий. Каждый поток состоит из восьми слоёв, которые и проводят векторный анализ.
Первый поток разбивает предложение на смысловые элементы и анализирует их, а второй высчитывает наиболее вероятный вариант перевода, исходя из контекста и модулей внимания.
Обратите внимание, что анализирующая сеть «читает» предложение не только слева направо, но и справа налево - это позволяет в полной мере понять контекст. Отдельно она формирует модуль внимания, с помощью которого второй поток понимает ценность отдельных смысловых фрагментов.
В нейронной системе наименьшим элементом является не слово, а фрагменты слова. Это позволяет сосредоточить вычислительные мощности не на словоформах, а на контексте и смыслах предложения. GNMT использует около 32000 таких фрагментов. По словам разработчиков, это позволяет обеспечить высокую скорость и точность перевода без потребления чрезмерных вычислительных мощностей.
Анализ фрагментов сильно уменьшает риски неточного перевода слов и словосочетаний с различными суффиксами, префиксами и окончаниями.
Система самообучения позволяет нейронной сети с высокой точностью переводить даже те понятия, которые отсутствуют в общепринятых словарях ![]() - сленг, жаргонизмы или неологизмы.
- сленг, жаргонизмы или неологизмы.
Но это ещё не всё. Нейросеть может работать и побуквенно. К примеру, при транслитерации имён собственных с одного алфавита на другой.
Статистика: действительно ли стало лучше?
С момента запуска системы GNMT прошло 2 года, поэтому можно оценить результаты.
Почему именно сейчас? Дело в том, что нейронная система работает без установленной базы данных, и ей требуется время, чтобы построить и скорректировать методы перевода.
К примеру, настройка машинной модели перевода, которая использует статистические методы, занимает от 1 до 3 дней. При этом построение нейронной модели такого же размера займёт больше 3 недель.
Примечательно, что при увеличении базы время на обработку статистической модели растёт в арифметической прогрессии, а для нейронной сети - в геометрической. Чем больше база, тем больше разрыв во времени.
А если учесть, что Google Translate работает с 10000 языковых пар (103 языка), то понятно, что адекватные итоги можно подводить только сейчас.
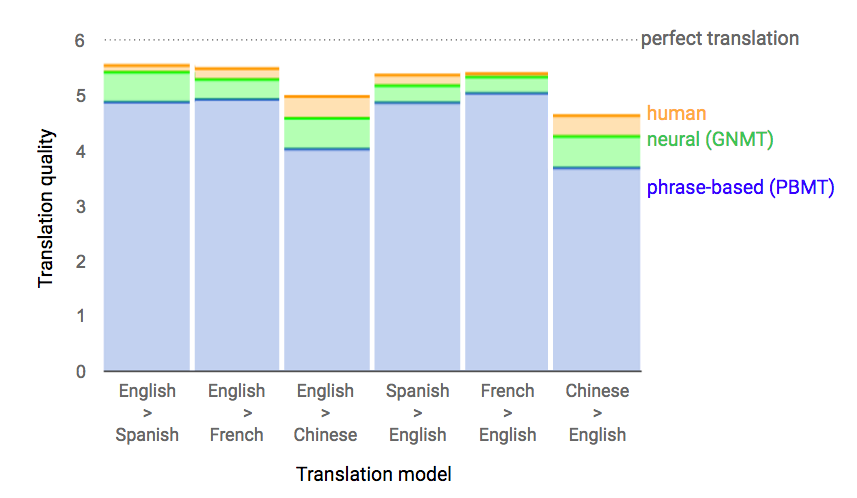
В ноябре 2016 года после полного окончания обучения системы и официального запуска аналитики Google представили подробный анализ результатов GNMT. Из него следует, что улучшения в точности перевода несущественные - в среднем 10%.
Наибольший прирост дали самые популярные языковые пары вроде испанский-английский или французский-английский - с результатом точности в 85-87%.
В 2017 компания Google проводила масштабные опросы пользователей Google Translate: их просили оценить 3 варианта переводов: машинный статистический, нейронный и человеческий. Здесь результаты оказались более интересными. Перевод с помощью нейросетей в некоторых языковых парах оказался очень приближён к человеческому.
Как видите, качество перевода в языковых парах «английский-испанский» и «французский-английский» практически соответствует человеческому. Но это и не странно, ведь именно на этих языковых парах происходило глубокое обучение алгоритмов.
С другими языковыми парами ситуация не такая радужная, но масштабного исследования по ним нет. Тем не менее, если со схожими по структуре языками нейронный перевод работает вполне хорошо, то с кардинально разными языковыми системами (например, японский ![]() и и русский) перевод заметно уступает человеческому.
и и русский) перевод заметно уступает человеческому.
При этом стоит заметить, что разработчики при запуске нейронной сети не пытались достичь максимальной точности перевода. Всё потому, что он потребовал бы сложных эвристических конструкций, а это сильно снизило бы скорость работы системы. Разработчики постарались найти баланс между точностью и скоростью работы. На наше субъективное мнение, это у них получилось.
И небольшой бонус напоследок
Специалисты утверждают, что если нейронная система Google Translate научится оперировать не только текстами, но также и аудио- и видеофайлами, то в таком случае нужно ожидать резкий скачок в развитии машинного перевода. Первые шаги в этих сферах уже сделаны, активно ведутся разработки новых алгоритмов для анализа видео и аудио. Поэтому пользователи могут уже в ближайшие несколько лет ожидать новых сюрпризов от Google.
Впервые опубликовано на сайте Cossa.ru
хостинг для сайтов © Langust Agency 1999-2024, ссылка на сайт обязательна
