11/06/2019 В начале было слово… а в конце его уже не было
Впервые опубликовано на сайте «Системный Блокъ»
На сайте «Системный Блокъ» была опубликован перевод статьи об английской литературе ![]() .
.
Ниже материалы статьи приведены полностью.
Почему в начале английского романа ты должен пообедать, а в конце жениться… или умереть?
Рассказываем, когда у мистера Дарси ![]() наступает кризис среднего возраста, Оливер Твист
наступает кризис среднего возраста, Оливер Твист ![]() превращается из мальчика в тинейджера, а главное, при чём тут ключевые слова и как они могут влиять на структуру романного сюжета?
превращается из мальчика в тинейджера, а главное, при чём тут ключевые слова и как они могут влиять на структуру романного сюжета?
Если вам срочно понадобилось написать роман, скорее всего, вы начнёте придумывать сюжет. Но есть ли какие-то правила, по которым надо его строить? И что мы вообще знаем о внутренних законах повествования? Существует ли рецепт универсальной сюжетной структуры романа, и если да, то как его найти?
Ответы на эти вопросы ищет Дэвид МакКлюр и команда из Cтэнфордской литературной лаборатории под руководством Марка Элджи-Хьюитта. Чтобы понять, как формируется «традиционный» английский сюжет, исследователи составили корпус из ~50 тысяч английских романов и посчитали, как 50 самых употребимых английских слов распределяются внутри повествования, выделив те слова, которые встречаются в текстах наиболее неравномерно.
Как это устроено?

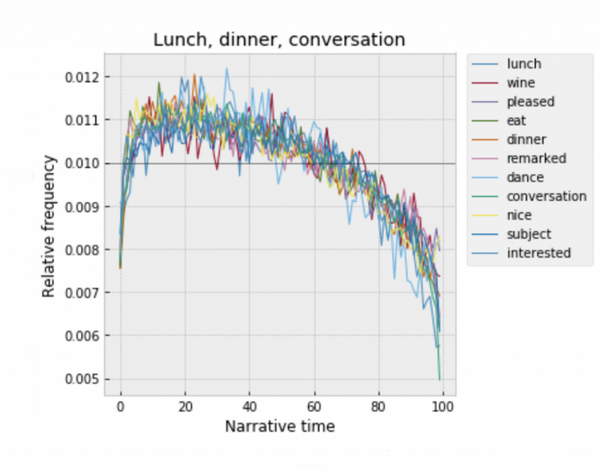
Каждый текст корпуса делится на N одинаковых по размеру фрагментов. Дальше мы можем подсчитать, сколько раз нужное нам слово повторяется в каждом из них во всех романах сразу. Например, слово «любовь» встречается 9 418 раз в первой из 100 частей повествования (1/100), а в последней, 100/100 - 25 132 раза. При помощи этой простой классификации можно представить, как любое слово распределено по времени повествования и сравнить график с тем, что ожидалось бы при равномерном распределении слов по тексту.
Это очень простой и наглядный способ оценить семантическую нагрузку каждого слова, и определить имеет ли наша «любовь» (или «смерть») тенденцию группироваться в какой-то части текста.
Результаты таких подсчётов часто подтверждают общие представления о жанровых конвенциях и законах повествования. Начало чаще всего заполнено описаниями людей, мест и вещей, рождения, детства, юности, образования, перечислениями семейных отношений.
Оружие, смерть, война и правосудие доминируют в последних частях романов (95%) и достигают пика употребления в кульминационных моментах. В финалах романов выбор невелик, там царят брак и смерть. Чем ближе к концовке, тем ярче становится выражение эмоций, как счастливых, так и печальных.
Некоторые слова демонстрируют и менее очевидные закономерности. Например, всё, что связанно с едой, разговорами и женскими персонажами, группируется в первых 10-20% повествования. Обед или званый ужин - очень удобный способ «познакомить» и «представить» читателю действующих лиц (вспомните ту же «Войну и Мир» ![]() или «Лунный Камень»).
или «Лунный Камень»).
В середине романа у героя зачастую случается внутренний кризис и переоценка ценностей: на отметке 50% доминируют слова, связанные с рефлексией, психологическим опытом и мыслью.
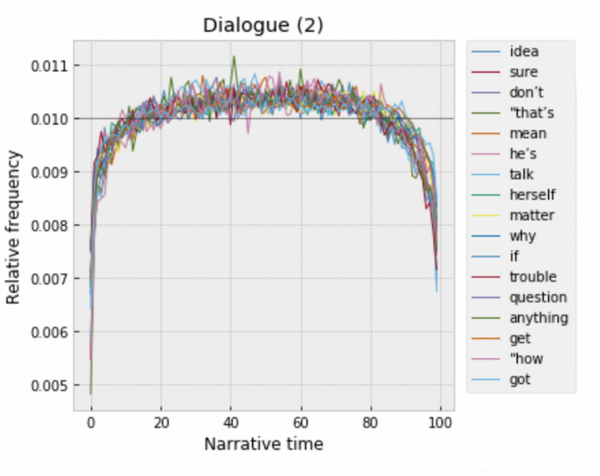
Но помимо анализа смысловых слов интересные результаты показывает и распределение служебных частей речи. Оказывается, что «a», «an» и «the» тоже имеют очень нерегулярное распределение внутри повествования. Неопределённые артикли активно употребляются в завязке, потом в первых 20% текста их количество резко уменьшается, они продолжают медленно снижаются в течении всего действия и снова резко падают в конце.
Видимо уменьшение употребления «а» и «an» связано с тем, что в английском они чаще всего используется, когда объект или субъект упоминается впервые. Соответственно, в начале, пока мы ещё не знакомы с героями и местом действия, неопределённые артикли «а» и «an» будут встречаться нам чаще, а в дальнейшем повествовании заменятся определённым «the».
 |
 |
Однако распределение «the» внутри романного времени тоже оказывается загадочным. Как и «a», «the» часто встречается в начале, но потом его употребление резко падает. Артикль практически отсутствует в середине и снова активно используется в конце.
Это немного не вписывается в нашу концепцию замены «а» на «the», но зато определяет новую интересную закономерность: если частота употребления «а» и «an» максимально отличается в начале и в конце текста, то «the», наоборот, сглаживает картину, сближая начало и финал.
Если мы посмотрим на распределение союза «оr», то увидим, простую, логичную закономерность - чем ближе к финалу, тем меньше противительных союзов. «Оr» - это всегда выбор, потенциальная развилка сюжета, а чем ближе конец, тем меньше вариативность событий. (если это, конечно, не «Тайна Эдвина Друга»).
Благодаря такому сквозному количественному анализ мы можем увидеть и определить множество интересных закономерностей. Но далеко не все из них находят логичное и простое объяснение. Например, на графике распределения личных и притяжательных местоимений «he»/«his» и «she»/«her» мы видим, что притяжательные местоимения к концу романа употребляются чаще, чем личные.
Значит ли это, что по мере развития действия герои превращаются в грамматические объекты и что в начале романа они что-то делают, а в конце что-то чаще делают с ними? Очень вряд ли (если, конечно, все 50 тысяч наших романов не похожи на «Превращение» ![]() и «Портрет Дориана Грея»
и «Портрет Дориана Грея» ![]() ).
).
Количественный анализ слов внутри отрезков повествования - не универсальный, но очень интересный метод. Особенно здорово, что он даёт нам возможность не только определять общие тенденции, но и наоборот находить тексты, в которых распределение ключевых слов максимально не похоже на общее.
© David William McClure, Scott Enderle, Ксения Костомарова
Впервые опубликовано на сайте «Системный Блокъ»
хостинг для сайтов © Langust Agency 1999-2024, ссылка на сайт обязательна
